Scaling across Multiple Regions
A user from South Korea brought to our attention that Pinggy works great for them, but it is slow. The answer to “why” was obvious to us. Pinggy was hosting its servers in the USA, specifically in Ohio. One key goal of Pinggy is to provide not only tunnels but fast and reliable tunnels. To improve the situation, we decided to host the tunnels in the region nearest to where the user is creating the tunnel from (as the default behavior).
Today, Pinggy is hosted across three regions: US, Europe, and Asia.
To scale across multiple regions, we did the following:
- Spawn edge nodes in multiple regions.
- Host our own DNS server to dynamically point tunnel traffic to the correct edge.
- Use AWS Route 53 for latency-based routing.
- Implement a central coordinator to handle authentication, sessions, etc.
The Problem
A Pinggy tunnel has two legs.
- One from the tunnel creator (client) to the Pinggy servers:
client <-> pinggy - The other from the Pinggy servers to the tunnel visitors (visitor):
pinggy <-> visitor
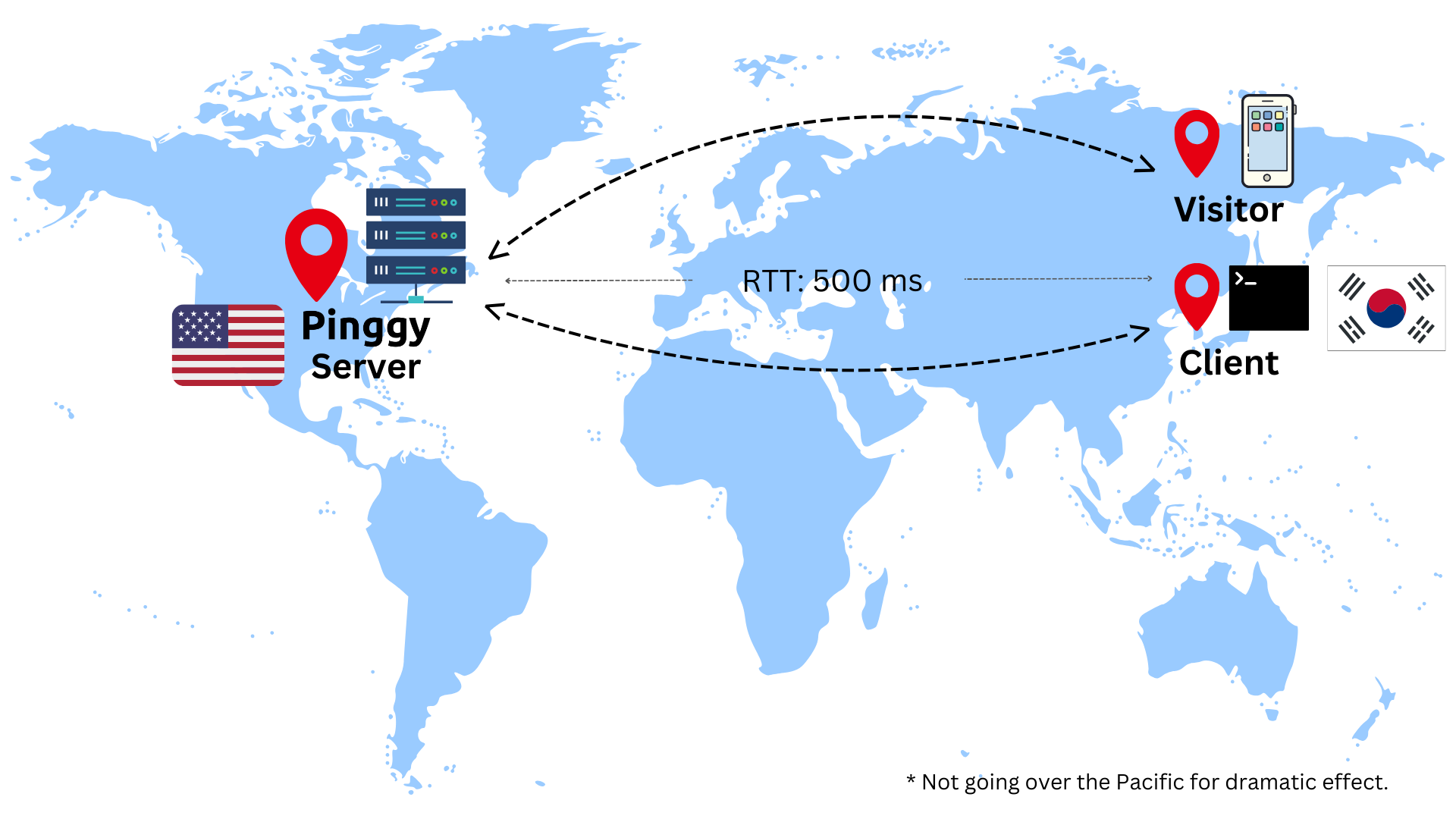
A visitor’s request to access a service through a Pinggy tunnel has to travel the entire path: visitor -> pinggy -> client.
This is followed by the response travelling the path client -> pinggy -> visitor.
Therefore, the entire journey is: visitor -> pinggy -> client -> pinggy -> visitor.
One can already imagine the latency if both the client and the visitor are in South Korea while the Pinggy server is in USA. The round trip time (RTT) can be as high as 500 ms from the visitor to the client (see the diagram below).
Refactor into core and edges
A Pinggy tunnel works in two phases: (a) Tunnel setup and (b) Tunnel live
(a) Tunnel setup: The user’s ssh client requests a tunnel with an access token and other configurations such as key-authentication, IP whitelists, header manipulations, etc. The Pinggy server has to (i) authenticate the request, (ii) check if an existing tunnel with the same token (same domain) is active or not, (iii) forcefully close any existing tunnel if required, and perform several other business logic before the tunnel can be started. For all these steps, database access (both reads and writes) is required.
(b) Tunnel live: Once the tunnel setup is complete, an active tunnel handles visitor traffic efficiently without touching the database that often.
Therefore, we have split the Pinggy server into core and edge. The core handles the business logic and then offloads the visitor traffic handling responsibility to the edges.
Multiple instances of the edges are then deployed in multiple regions, all connected to a single core and hence a single database. By a single core and database, we mean that the core and the database are located in a single region only.
As a result, the latency for creating a tunnel stays more or less the same, since when a client initiates a tunnel creation process, the requests flow through as follows: client -> edge -> core, instead of client -> core like before. Here the edge is located very close to the user initiating the tunnel, and we can assume that they are practically co-located.
Once the tunnel is live, the visitor traffic flows in a much more efficient path: visitor -> edge -> client -> edge -> visitor.
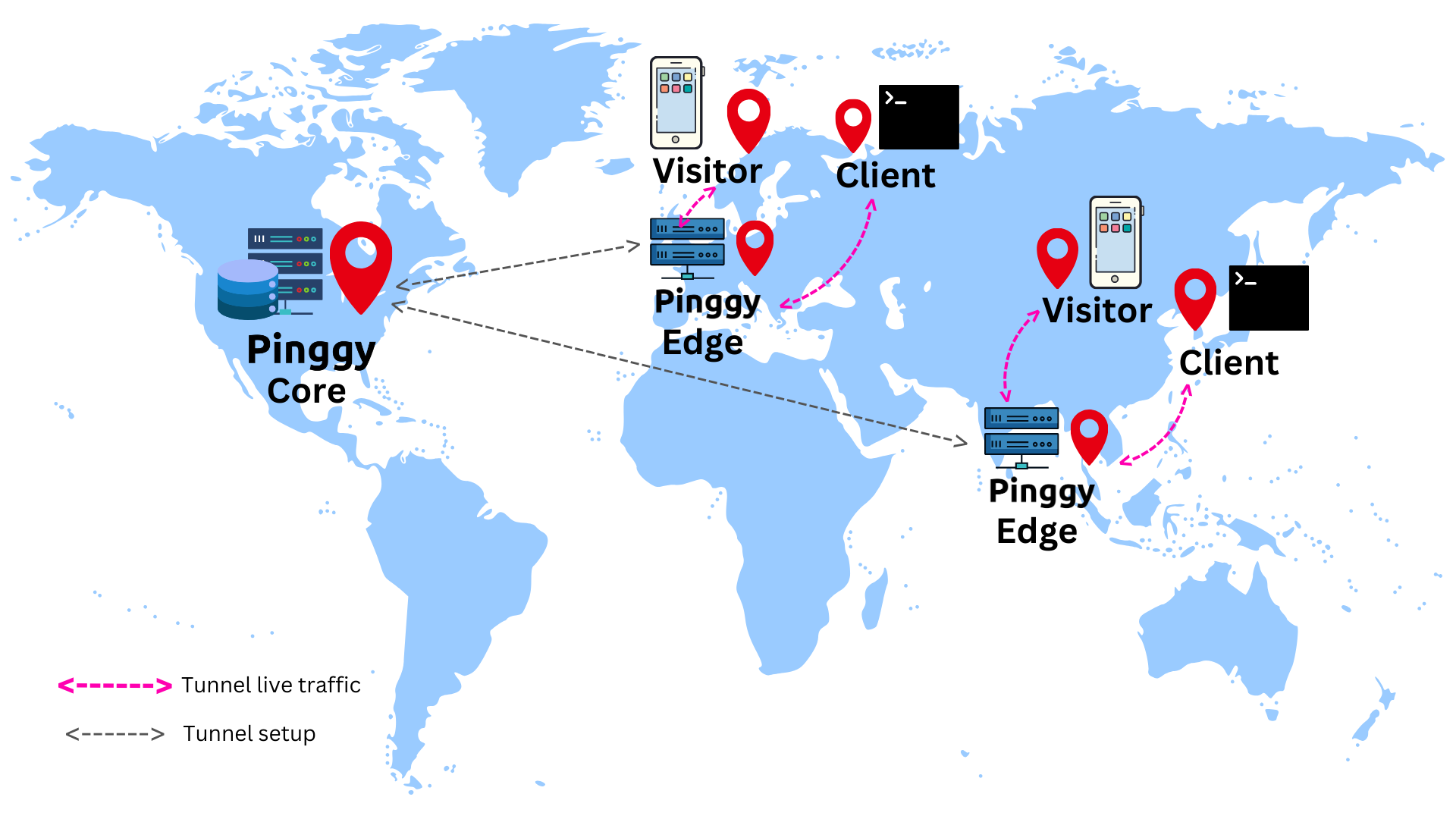
From the above image, it becomes clear that the edge handles all the visitor traffic. As a result, the visitor has a much better experience. The high latency from an edge to the core does not impact the visitor traffic. An edge consults the core first when a tunnel is being created, and then less frequently and asynchronously, without affecting the visitor traffic.
One might ask the question, what if the visitor and the client are in two far away regions. Even if we think about a direct link from the visitor to the client, then also the latency will be high as they are located far away geographically. However, we cannot make the communication link faster magically. What we try to do is place the Pinggy edge as close to the client as possible. Therefore, the edge <-> client link has very low latency and the overall latency of a visitor is very similar to the visitor <-> client latency.
Dynamic DNS updates
The most challenging part of this entire process of multi-region scaling is handling the DNS. To understand the problem one must understand what Pinggy offers in terms of domain names first.
Pinggy offers (i) persistent subdomains (e.g. androidblog.a.pinggy.io) as well as (ii) custom domains (e.g. mydomain.com). A custom domain simply points to a persistent subdomain through a CNAME record.
When a tunnel is created, the persistent subdomain has to point to the server where the tunnel is running. Therefore, ultimately the subdomain must be resolved to A or AAAA records pointing to the correct Pinggy server.
With a single Pinggy server, it was very simple. Every subdomain pointed to the single server (e.g. 1.2.3.4). Therefore, a resolution would look like:
mydomain.com --CNAME--> androidblog.a.pinggy.io --CNAME--> *.a.pinggy.io
*.a.pinggy.io --A--> 1.2.3.4
But with multiple regions we have multiple edges with separate IPs. For example:
USA: us.a.pinggy.io --A--> 1.2.3.4
Europe: eu.a.pinggy.io --A--> 5.6.7.8
Asia: ap.a.pinggy.io --A--> 9.0.1.2
Depending on where the user is located, i.e. in which edge it is creating the tunnel, the tunnel’s domain name records need to change.
If a user connects to the USA edge, then the domain should point to that edge:
mydomain.com --CNAME--> androidblog.a.pinggy.io --CNAME--> us.a.pinggy.io
But if a user connects to the Europe edge:
mydomain.com --CNAME--> androidblog.a.pinggy.io --CNAME--> eu.a.pinggy.io
We can not limit the user to a single location. A user’s client should ideally connect to the nearest edge and initiate a tunnel through that. Some users use Pinggy tunnels on VMs which are often located in different regions. Therefore, a user account cannot be tied to a single region. The DNS has to be handled by us.
Why Route 53 does not work here?
Our first intuition was to use some hosted DNS provider that also provides APIs to update records dynamically. AWS Route 53 is one such highly available and scalable Domain Name System (DNS) web service. But Route 53 does not fit our requirements.
The specific reason is that the edge locations of Route 53 can take up to 60 seconds to be updated after a record set is changed.
“There are over 100 edge locations in Route 53 with DNS name servers that answer DNS queries from clients. When you update a record set in your hosted zone, the change propagates to all Route 53 edge locations within 60 seconds.” - AWS Knowledge Center
In our use case, the moment a client tries to create a tunnel, first the DNS records have to be updated, then the tunnel starts, and then the URL is given to the user. Since Route 53 edge locations take up to a minute to start, when a user tries to access the tunnel URL immediately after the tunnel is created, the DNS either (i) resolves to an incorrect record, or the (ii) record is simply not found. The latter scenario is even more problematic.
(i) Expired record: If the tunnel with the same subdomain / custom domain is created in USA first, then disconnected, then again connected through Europe, then the Route 53 records will point to the USA edge instead of the Europe edge for up to a minute. If that incorrect record is resolved by some visitor in the meantime, then not only the tunnel will stop working but also will continue to be dysfunctional till the TTL of the record expires. After the TTL expires and the DNS is queried again, the correct name resolution will take place. A low TTL such as 10 seconds makes sense, but the Route 53 records will in any case take up to one minute.
(ii) No record: Suppose no records exist against the tunnel subdomain / custom domain. Then, after the tunnel is created, if a visitor visits the tunnel URL immediately, then it might happen that the domain fails to resolve since Route 53 records have not been propagated. We faced this issue in our tests very frequently. In this case, low TTL also does not work, and the SOA record needs to have a very low TTL also.
You can read more about these issues this blog post.
Hosting our own DNS server
Fast updation of DNS records is an essential requirement for reliable Pinggy tunnels. Therefore, we host our own instances of PowerDNS. This choice has some obvious disadvantages like managing an extra piece of infrastructure, not having DNS servers present in as many regions as in the case of Route 53, etc.
PowerDNS authoritative server allows us to manage our DNS zone. We are able to update records immediately and more importantly synchronously before the tunnel creation process is complete. We also set low TTLs as and when required. As a result, when the tunnel creation process is complete, the authoritative server already has all the records in place.
Over the past couple of months, our PowerDNS instances have been working very well. Updates are fast, and we can also keep the SOA record TTL low. Notably, PowerDNS is very efficient and consumes very low memory and CPU resources.
However, one major problem we faced was no simple or reliable way of latency-aware routing. For that we had to again use Route 53 separately.
Latency aware routing
Ideally, a client trying to initiate a Pinggy tunnel should connect to its nearest edge. The client here is usually the ssh client. Unlike HTTP requests, we cannot redirect the ssh client’s TCP connection to some place else through application layer logic. Instead, we need to handle this with DNS only. Therefore, a.pinggy.io should resolve to the nearest among us.a.pinggy.io, eu.a.pinggy.io, and ap.a.pinggy.io.
Route 53’s latency-based routing solves this exact problem. Since our infrastructures are hosted on different AWS regions, we create different latency records for them. When a DNS query arrives at Route 53, it computes the nearest region and answers the query with the corresponding latency record.
For a client connecting from New York, the DNS resolution is:
a.pinggy.io --CNAME--> us.a.pinggy.io
The same for a client from Japan is:
a.pinggy.io --CNAME--> ap.a.pinggy.io
End-to-end flow
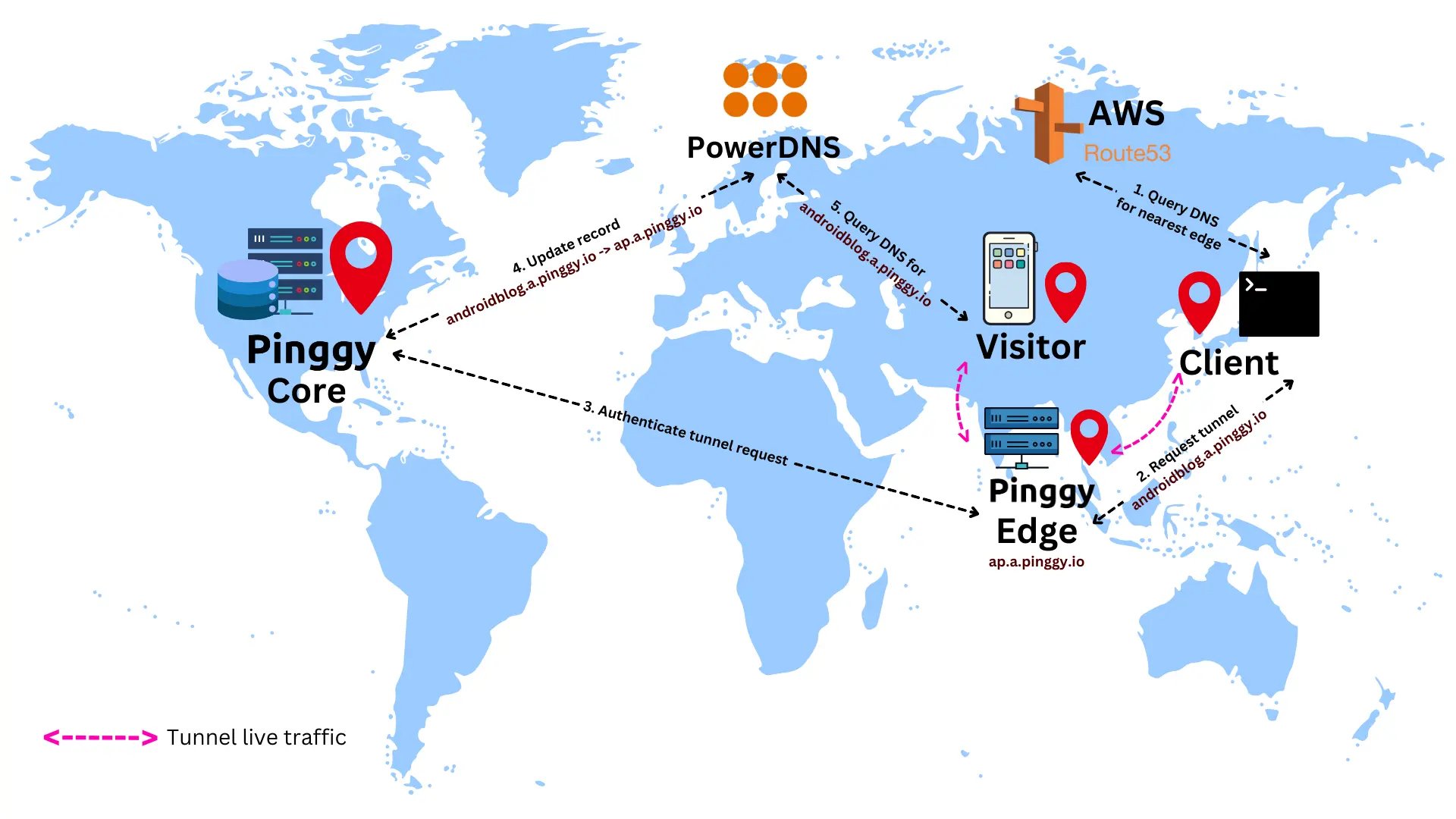
The following end-to-end flow will help one to understand how the Pinggy edge, core, PowerDNS and Route 53 are working together to create the tunnels in this multi-region setup.
- A Pinggy client, which is some ssh client tries to connect to the nearest edge. This is done by resolving the domain name
a.pinggy.io. - This DNS query is handled by AWS Route 53, and resolves to the nearest edge server among USA:
us.a.pinggy.io, Europe:eu.a.pinggy.io, and Asia:ap.a.pinggy.io. - client requests the edge (say
ap.a.pinggy.io) for a tunnel with a subdomainandroidblog.a.pinggy.io. - The edge performs some API requests to the core to authenticate the client, validate the subdomain, and to ensure that no tunnels with the same subdomain are active.
- Once the tunnel is authenticated and ready to be activated, a DNS record is created in the PowerDNS servers:
androidblog.a.pinggy.io -> ap.a.pinggy.io. - The tunnel becomes live.
- A visitor trying to access
androidblog.a.pinggy.ioresolves the domain name from our PowerDNS servers. PowerDNS responds withap.a.pinggy.io. - The visitor to client tunnel thus works as follows:
visitor <-> edge (Asia) <-> client.
Conclusion
We are still in our early stages of scaling Pinggy. Our first priority is always reliability, followed by performance. Therefore, we are focusing on improving the availability by having multiple instances and automatic failovers. Failovers for web applications are much simpler since it means routing HTTP requests to a different location. But if a pinggy edge stops, the tunnel disconnects. Transferring a live SSH tunnel to a different server is a challenging and open research question. We leave that for the future. For now, we are focusing on trying to make the edges as resilient as possible.